
The Data Blog |
|
At first, test data and training data may seem like the same thing, however there are several fundamental differences between the two that can make or break your data model. Training Data is used to build or create a model in its earlier stages and can be implemented to help the model run. Training Data is often found in machine learning to ensure the data model can be "trained" to perform several actions, and ensuring the future development of the API and algorithms that a machine will continuously work with. Test Data on the other hand are datasets which are used to validate existing data models to make sure algorithms produce correct results, machine learning is happening correctly, and output which mirrors intended findings are consistent. Alternatively, test data can be used to invalidate a data model and disprove it's efficiency, or find that a data model or AI may be producing sub-optimal results and therefore may need further tests or different kinds of training to reach maximum efficiency. Below, is a diagram depicting the data training, validation, and testing model and the different steps that may be encompassed throughout the different processes. 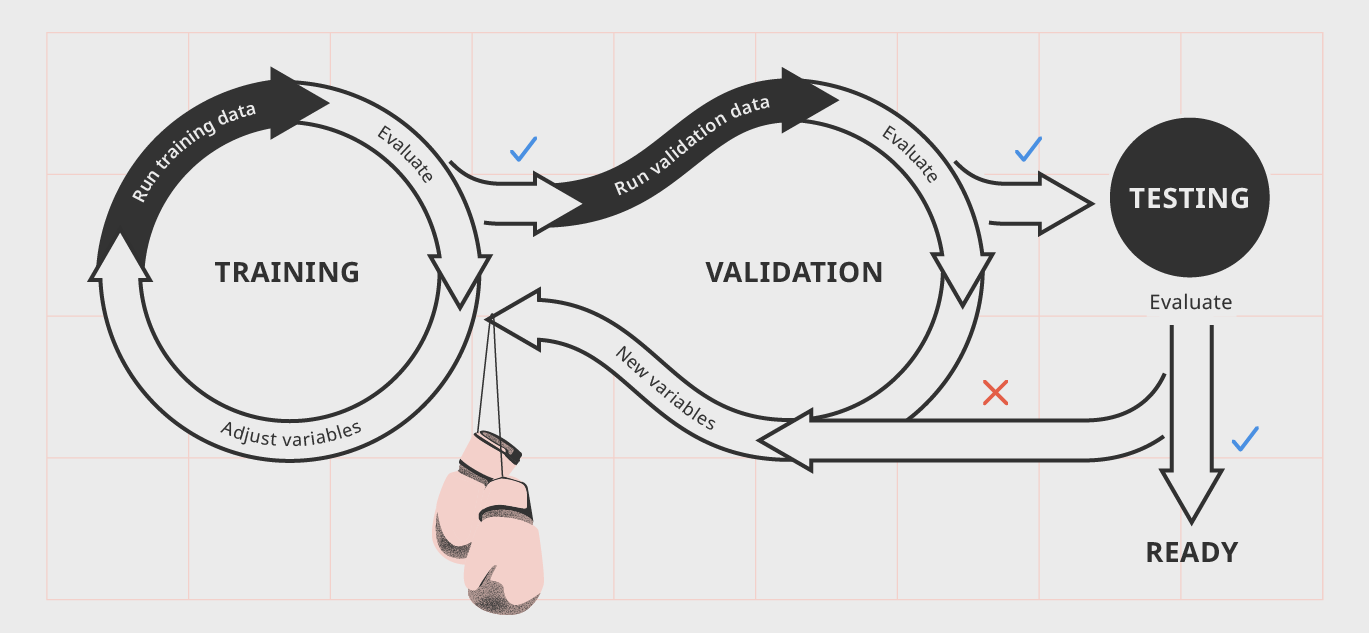 Training and test data models Training AI or any sort of machine learning is a rigorous process that requires a fair amount of training, validation, and testing, and it's very rare a data model is perfected on its first try. That's why it's important for training and test data to be differentiated; otherwise, results will appear too similar, leading observations and evaluations for both datasets to be inconclusive, ensuring more testing and validation would have to be done.
0 Comments
Leave a Reply. |
Archives
August 2023
Categories
All
Data Blog |
 RSS Feed
RSS Feed