
The Data Blog |
|
At first, test data and training data may seem like the same thing, however there are several fundamental differences between the two that can make or break your data model. Training Data is used to build or create a model in its earlier stages and can be implemented to help the model run. Training Data is often found in machine learning to ensure the data model can be "trained" to perform several actions, and ensuring the future development of the API and algorithms that a machine will continuously work with. Test Data on the other hand are datasets which are used to validate existing data models to make sure algorithms produce correct results, machine learning is happening correctly, and output which mirrors intended findings are consistent. Alternatively, test data can be used to invalidate a data model and disprove it's efficiency, or find that a data model or AI may be producing sub-optimal results and therefore may need further tests or different kinds of training to reach maximum efficiency. Below, is a diagram depicting the data training, validation, and testing model and the different steps that may be encompassed throughout the different processes. 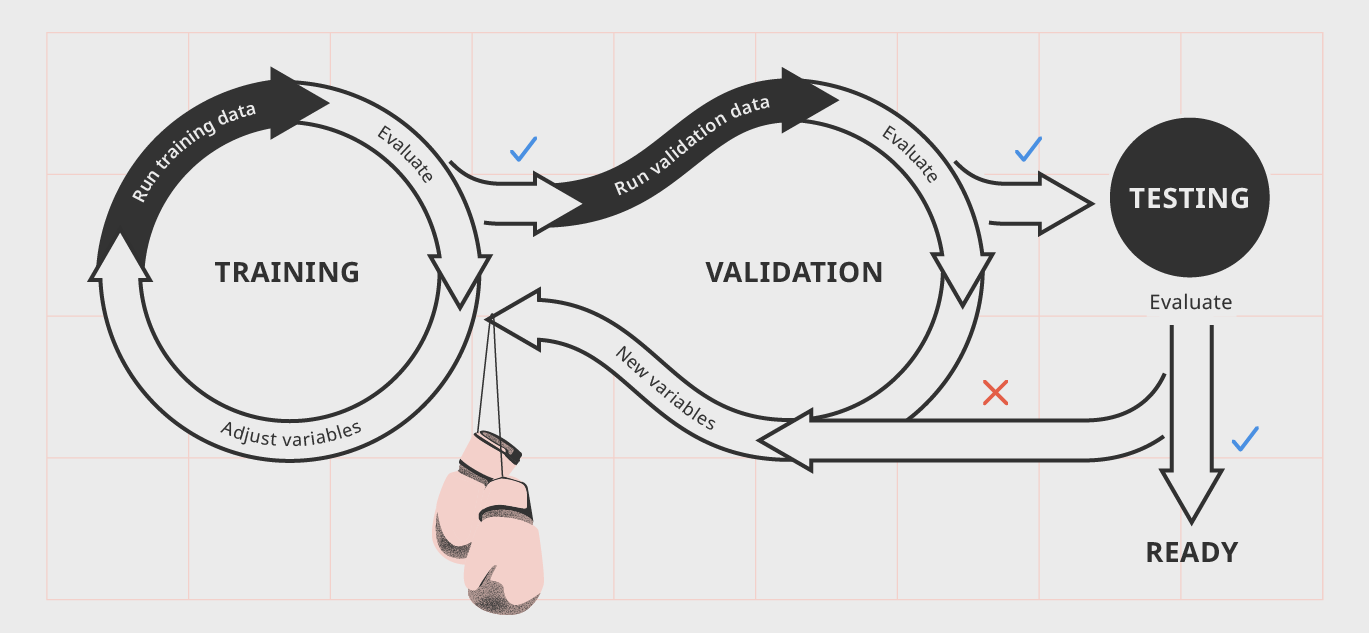 Training and test data models Training AI or any sort of machine learning is a rigorous process that requires a fair amount of training, validation, and testing, and it's very rare a data model is perfected on its first try. That's why it's important for training and test data to be differentiated; otherwise, results will appear too similar, leading observations and evaluations for both datasets to be inconclusive, ensuring more testing and validation would have to be done.
0 Comments
Banking, insurance, and financial applications are apart of the largest sector for consumer IT services and carry very confidential information pertaining to their day to day user base. Banking software must be free of error not only to ensure the best possible customer service, but because hackers can exploit potential bugs in the application and access private financial data, which may compromise the assets of many individuals using said banking, insurance or financial services.
Thus, it becomes essential that every iteration of banking applications are tested profusely before rolling out to the live servers. When used with test data, banking applications can simulate live consumer interactions with minimal risk to all parties involved. Test data can be used throughout each phase of the testing process including but not limited to database testing, integration testing, and security testing. For example, test data can be used for security verification and validation processes to ensure only those with the correct permissions can access their data. 60 percent of breaches are linked to a third party. Why are you giving them access to your data when you don't need too?
Third-party contractors are the biggest source of security incidents outside of a company’s employees:
Why are commercial companies and government agencies giving access to their private and confidential data to third parties when there exist viable technology alternatives to this practice and they don't need too? With the rise of social media in our current day and age, it's only natural that test data is utilized to ensure platforms such as Facebook, Twitter, and Instagram are working as intended to their highest degree of efficiency. Test data is utilized both for desktop and mobile applications for the social media platforms and is generated for many different use cases. One particular use case for test data in social media applications is for encryption so that user data remains private and isn't accessible to those who shouldn't have it.
Furthermore, user data and test user data are used by platforms such as Facebook and LinkedIn to generated sponsored and tailored content for each specific individual. Each user's data is different to a degree and thus generated test data must be dynamic enough to be manipulated to represent the millions of user-types the social media world may have. A thought exercise on the System perspective of dev and test, as enabled by ExactData Synthetic Data. Let’s consider the development of an application that scours incoming data for fraudulent activity… How would that test and analysis look with production data, de-identified production data, hand crafted data, and ExD synthetic data? Let’s also consider that the application will classify all transactions/events as either bad or good. The perfect application would classify every transaction correctly resulting in 100% Precision (everything classified as bad was actually bad), 100% capture rate (classified every actual bad as bad), 0% escape rate (no bads classified as good), and 0% False Positive rate (no goods classified as bad). The application needs to be developed, tested, and analyzed from a System perspective. For example, the application could classify every transaction as bad and achieve 100% capture rate, and 0% escape rate, but would also result in poor Precision and a huge False Positive rate – thus requiring significant labor support to adjudicate the classifications. On the other extreme, the application could classify everything good, be mostly right, and not catch any bads. Both of these boundary conditions are absurd but illustrate the point of the importance of System. One method of System analysis is the Confusion Matrix, noted below. 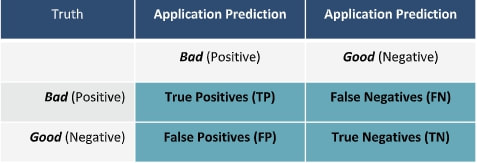 With production data, you don’t know where the bads are, so you can’t complete the confusion matrix.
With de-identified production data, you don’t know where the bads are, so you can’t complete the confusion matrix. With hand-crafted data, you might have the “truth” to enable completion of the confusion matrix, you would not have the complexity or volume to be truly testing to find the “needle” in the haystack of fraudulent behavior within mass of good behavior. With ExD synthetic data, you know where every bad is (you have the ground truth), so you CAN complete all 4 quadrants of the confusion matrix, and can then only, conduct a system analysis, driving the application to the real goal of tuning and optimizing Precision (maximizing TP) and Capture rate (maximizing TP/TP+FN) , while at the same time minimizing Escapes (FN) and False Positive rate (FP/FP+TP). Within a particular setup of an application version, these are typically threshold trade-offs, but with next iteration development, there is the opportunity to improve on all scores. |
Archives
August 2023
Categories
All
Data Blog |
 RSS Feed
RSS Feed