
The Data Blog |
|
According to VentureBeat, AI is facing several critical challenges. Not only does it need huge amounts of data to deliver accurate results, but it also needs to be able to ensure that data isn’t biased, and it needs to comply with increasingly restrictive data privacy regulations.
We have seen several solutions proposed over the last couple of years to address these challenges, including various tools designed to identify and reduce bias, tools that anonymize user data, and programs to ensure that data is only collected with user consent. But each of these solutions is facing challenges of its own. Now we’re seeing a new industry emerge that promises to be a saving grace: synthetic data. Synthetic data is artificial computer-generated data that can stand-in for data obtained from the real world. A synthetic dataset must have the same mathematical and statistical properties as the real-world dataset it is replacing but does not explicitly represent real individuals. Think of this as a digital mirror of real-world data that is statistically reflective of that world. This enables training AI systems in a completely virtual realm. And it can be readily customized for a variety of use cases ranging from healthcare to retail, finance, transportation, and agriculture. Over the last few years, there has been increasing concern about how inherent biases in datasets can unwittingly lead to AI algorithms that perpetuate systemic discrimination. In fact, Gartner predicts that through 2022, 85% of AI projects will deliver erroneous outcomes due to bias in data, algorithms, or the teams responsible for managing them. One alternative often used to offset privacy concerns is anonymization. Personal data, for example, can be anonymized by masking or eliminating identifying characteristics such as removing names and credit card numbers from ecommerce transactions or removing identifying content from healthcare records. But there is growing evidence that even if data has been anonymized from one source, it can be correlated with consumer datasets exposed from security breaches. In fact, by combining data from multiple sources, it is possible to form a surprisingly clear picture of our identities even if there has been a degree of anonymization. In some instances, this can even be done by correlating data from public sources, without a nefarious security hack. Synthetic data promises to deliver the advantages of AI without the downsides. Not only does it take our real personal data out of the equation, but a general goal for synthetic data is to perform better than real-world data by correcting bias that is often ingrained in the real world.
0 Comments
Synthetic data is consistently able to fill the gaps where real-world data can't quite manage to hit the mark. Whether it's for the advancement of artificial intelligence or enhancement of robust simulations, synthetic data has one thing that real-world data never will have; controlled variation.
Synthetic data being created artificially gives a major advantage which allows us to control test conditions and variations within the data. Instead of needing to rely on real-world data to satisfy every single test condition you can think of, synthetic data fills each of those gaps with ease, and allows for not only progression, but automation as well. Soon, artificial intelligence will be able to improve itself by synthesizing its own simulated data and automate its own evolution. Think of it; if artificial intelligence is able to automate its own testing and training and improve itself until completion, there won't be a need for real-world data anymore. AI would just need to create its own data to adjust itself to, which let's face it, would cover more ground a lot more quickly than any non-synthetic data counterparts. For example, self-driving cars being able to calculate the quickest route to any given destination on the fly and adjusting accordingly based on upcoming traffic, accidents that may have occurred, or any other predicted trouble on the road would innovate the automobile industry to no end. This also begs the question, if everyone is using synthetic data for automation, who will do it best? Will AI compete with each other to automate itself best? Only time will tell. Artificial Intelligence has come a long way since the initial applications the technology was developed for, and advancements in the field yet again show another added benefit in the form of detecting COVID-19. Artificial Intelligence applications have been used to detect COVID-19 in patients and distinguish the virus from other diseases such as phenomena and other lung diseases. According to Jun Xia from Shenzhen Second People's Hospital's Department of Radiology, a learning model can be used so AI can accurately differentiate COVID-19 from different types of lung disease, while detecting whether or not one is positive for the virus as well.
Furthermore, the use of AI is used within contact tracing models to detect where the virus is spread and how severe it is in different given areas. Applications can currently track where the virus is and algorithms are being tested to not only track the virus but also predict where it will spread as well. This not only gives us a better fighting chance against COVID-19 but future pandemics as well. Finally, AI and machine learning are being used to accelerate medical drug treatment for COVID-19 to identify potential medications to help act as a treatment for the virus. BenevolentAI used machine learning techniques for this purpose to deduce that Baricitinib, a drug for rheumatoid arthritis, is a strong candidate to inhibit the progression of COVID-19 and is now in clinical phases to act as a treatment as a result. AI and machine learning have come so far in such a short amount of time, and as a result are helping us deal with real-world problems in more ways than one. At first, test data and training data may seem like the same thing, however there are several fundamental differences between the two that can make or break your data model. Training Data is used to build or create a model in its earlier stages and can be implemented to help the model run. Training Data is often found in machine learning to ensure the data model can be "trained" to perform several actions, and ensuring the future development of the API and algorithms that a machine will continuously work with. Test Data on the other hand are datasets which are used to validate existing data models to make sure algorithms produce correct results, machine learning is happening correctly, and output which mirrors intended findings are consistent. Alternatively, test data can be used to invalidate a data model and disprove it's efficiency, or find that a data model or AI may be producing sub-optimal results and therefore may need further tests or different kinds of training to reach maximum efficiency. Below, is a diagram depicting the data training, validation, and testing model and the different steps that may be encompassed throughout the different processes. 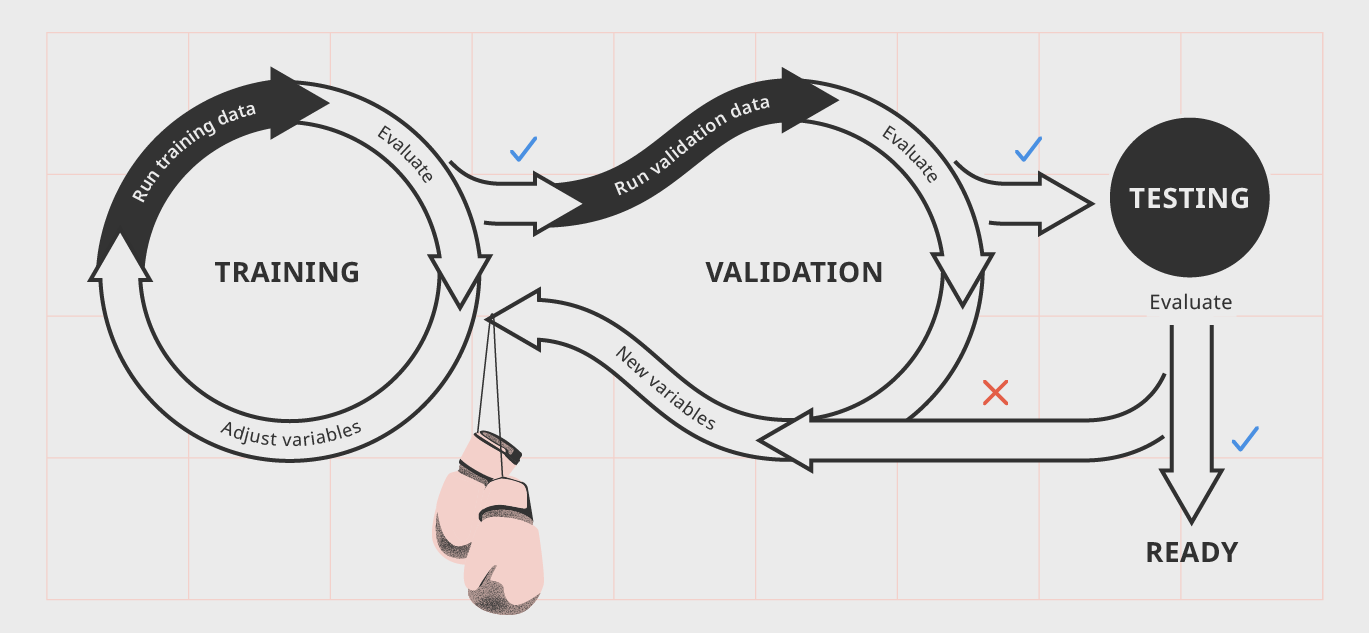 Training and test data models Training AI or any sort of machine learning is a rigorous process that requires a fair amount of training, validation, and testing, and it's very rare a data model is perfected on its first try. That's why it's important for training and test data to be differentiated; otherwise, results will appear too similar, leading observations and evaluations for both datasets to be inconclusive, ensuring more testing and validation would have to be done. What Test Data is Being Used Today and by Who?
An organization’s development ecosystem, including technical partners, software development and contractors have a growing need to access private and confidential data to do their jobs. Relevant data sources are a necessary component of the software development, technical integration, testing, implementation and ongoing operations and maintenance processes and production data sources are commonly accessed and modified for this purpose. Complex, integrated technology solutions can no longer be managed within an organization’s internal operations but requires a large and varied global ecosystem of partners, consultants, technology companies and contractors. There is a similar need for test data within the organizations cyber security operations. It is also common practice for this ecosystem to utilize historical data, captured network traffic and simple network traffic generation technology for testing purposes. With every new year comes exciting new updates and trends to the technological world around us! We at ExactData are excited about many trends and future advancements to come, but here are five that we're excited about in particular!
1) Advancement of AI and Mobile Intelligence It's no secret that AI and mobile intelligence are evolving everyday. We see growth in both of these departments to no end, where things like facial recognition, fingerprint, voice, and eyes scans are all becoming more of a reliable reality! This is seen through many of the innovations of Apple, Samsung, and Google have brought to the table, but also through other fields of data science as well! 2) Automation and Innovation When one thinks of automation and innovation, jobs and mundane tasks are often the first things thought of. How is data being innovated or automated you may ask? Well being able to derive data in faster response rates, being able to generate, switch, and use data for test purposes on the fly for exact results seems innovative to us! This innovation can be traced to artificial intelligence as well through pattern recognition, GPS sensors, self-driving cars, and more! 3) Cloud Computing and Cyber Security Cloud computing is becoming more distributed, meaning the origin of the cloud can distribute services to other locations while operating fully in effect from one area. Server updates, latency checks, and bandwidth fixes are becoming quicker every year which not only affects the cloud and its functions but can also be used to stop breaches, glitches, and hackers right in their tracks as soon as they get into the system. 4) Financial Patterns and Recognition Recognizing financial data patterns through data has been historically tricky due to the immense analytical prowess and and observational skills that could be needed. AI and statistical learning developments however can be trained to pick up these patterns more quickly than ever before, and with less error too. Financial analytics and trend recognition will certainly see upgrades in the upcoming year, especially with more variables such as cryptocurrency coming into play. 5) Accessibility and Privacy Accessibility and privacy for data files come hand in hand; by making something more accessible you also have the means to make it more restricted. Added levels of security for data can come in many different forms; test data, artificial data, cloud computing, advanced machine learning, more advanced security protocols and more. The rule of thumb is to keep everything private that you may need for later so that nobody else can take or modify it. While there are so many trends we believe to be up and coming in the world of data, these were just some of the few we believe to be relevant to both the industry and general public as a whole. Most scientists agree that no one really knows how the most advanced algorithms do what they do, nor how well they are doing it. That could be a problem. Advances in synthetic data generation technologies can help. These algorithms generate data with a known ground truth, sufficient volumes and with statistically relevant true and false positives (TP, FP) and true and false negatives (TN, FN) for the nature of the test. AI algorithms can now be measured for precision, c, as the fraction of the predicted matches that are true positive matches, or c = TP/(TP + FP).A very interesting application of high-fidelity synthetic data generation techniques is to reduce credit card fraud. By 2025, the global losses to credit card fraud are expected to reach almost $50 billion. Detecting fraudulent transactions in a large data-set poses a problem because they are such a small percentage of the overall transactions. Banks and financial institutions are in need of a solution that can correctly identify both fraudulent and non-fraudulent transactions, and detect false/true negatives and false/true positives, enabling the creation of receiver operating curves and tuning the system to optimize for the cost to correct the fraud payment versus the cost of the payment. High fidelity synthetic data solves this dilemma by generating volumes of non-fraudulent transactions while interweaving complex fraud patterns into a very small subset of the overall transactions. The fraud patterns are known, enabling the credit card fraud detection system to be optimized.
High interest helping to implement Cyber Behavioral Tools was expressed by many potential clients, including the Cyber Innovation Manager from one of the world's largest banks, a Divisional Chief Information Security Officer for one of the biggest US Federal Systems Integrator's and one of the largest Cyber Independent Testing Laboratories. During the demonstrations large amounts of internally consistent data was generated for all desired behaviors. Data was generated over any time-frame to output:
|
Archives
August 2023
Categories
All
Data Blog |
 RSS Feed
RSS Feed